I was recently tasked with backing up some databases to an Azure Storage Account, using BACKUP TO URL in SQL Server. It is quite simple. Create a Shared Access Token for the Storage Container and then create a CREDENTIAL in SQL Server using “shared access token” as identity and the access token as password.
In an Azure Storage Container, one writes either page blobs or block blobs. Think of a blob as a file in a file system. When SQL Server backups to an URL, it will create a block blob. The size limitation for a block blob in an Azure Storage Container is 200GB. For a large database, the backup file will be larger than 200GB and you will get some funny I/O device errors. The error message will not tell you that you hit the 200GB threshold, it will just tell you there was an I/O failure on the backup device. And that error won’t come at the start of the backup. It will come when SQL Server has written 200GB.
Why 200GB? The limitation is actually 50.000 blocks. A block can be up to 4MB. 50.000x4MB ~ 200GB. Use MAXTRANSFERSIZE for the backup command to set this size. Also use the BLOCKSIZE parameter for the backup command and set it to 64kB (65536 bytes) to maximize the maximum size of a single blob created by the 50 000 blocks in a blob.
BACKUP DATABASE [Underlandet] TO URL='https://saunderlandetdatabasebackups/productionbackups/underlandet.bak WITH BLOCKSIZE=65536, MAXTRANSFERSIZE 4194304, FORMAT, INIT, CHECKSUM, COMPRESSION
Ok, now that’s quite a limitation you might think. Large databases will get large backup files. Even with compression, large enough databases will have backup files larger than 200GB. You could of course backup different file groups to different backup files to overcome this limitation. But sooner or later, as your database and your file groups grow, you will hit the 200GB limit.
The way to overcome this limit is to stripe the backups to multiple files. You stripe a backup to multiple files by simply adding multiple URL=<storage container path> to your backup command. Something like this
BACKUP DATABASE [Underlandet] TO
URL='https://saunderlandetdatabasebackups/productionbackups/underlandet-1-of-2.bak,
URL='https://saunderlandetdatabasebackups/productionbackups/underlandet-2-of-2.bak
WITH BLOCKSIZE=65536, MAXTRANSFERSIZE 4194304, FORMAT, INIT, CHECKSUM, COMPRESSION
You can stripe a backup to up to 64 files. This gives you 200GB x 64 ~ 12,8TB, which at least for all the databases I normally work with is enough. If you still hit the size limit, you will have to split your database into multiple file groups and backup individual file groups instead of the whole database at once. If your database is THAT large, you probably have it split into multiple file groups already anyway (some of the file groups being read-only and not backuped with the same cadence as the read-write file groups).
Background to this post: I’m writing this post assuming you haven’t enabled read committed snapshoton your database. You will find DBAs online who tell you to just do it – it will solve all your locking problems. This is not the case. read committed snapshot is wonderful sometimes. But it comes with a cost. It’s not a one-size-fits-all solution to your blocking problems.
“Lock escalation in SQL Server”. Generated with Microsoft Copilot Designer
The business problem to solve
Consider the following SQL Server situation. You have a table with the really innovative name dbo.TableA. dbo.TableA has an identity column as Primary Key (and clustered key). You have an application that hammers dbo.TableA with single row inserts 24/7. This application uses SCOPE_IDENTITY() to figure out what value the identity column got for a single inserted row. You can’t change the application. And you are now given the task to move one billion rows from dbo.TableB. No rows may exist in both dbo.TableA and dbo.TableB at the same time.
Since you have an application hammering dbo.TableA with inserts, and this application relies on SCOPE_IDENTITY() to find the identity value for inserted rows, you can’t change the table to use a sequence to get default values – you need the identity column to stay an identity column. And you need to insert one billion rows into the table without causing blocking for the application hammering dbo.TableA with inserts.
What’s good for you though is that you don’t need to keep the PK value from dbo.TableB when it’s inserted into dbo.TableA. This is a made-up business case, but I was tasked with something very similar recently, and that gave me the idea to write this blog post.
First attempt. The naive approach.
Your first attempt to solve this problem may be as simple as:
BEGIN TRAN
INSERT INTO dbo.TableA (c1, c2, c3,..,cN)
SELECT c1, c2, c3,..,CN) FROM dbo.TableB
DELETE dbo.TableB.
COMMIT
Looks easy, right? But we’re talking about billions of rows in dbo.TableB. And users will not be happy if you block dbo.TableA. And inserting billions of rows into a table will cause blocking. Why? Because this single insert will first set PAGE-locks. These PAGE-locks will be exclusive locks, meaning no other session can read from or write to the pages. And sooner rather than later, there will be so many locks from this transaction, that lock escalation will happen. Lock escalation is when a single transaction has created so many locks that SQL Server decides it’s getting a bit much to handle, and changes the PAGE-locks to OBJECT locks. OBJECT locks in this case means TABLE locks. An exclusive OBJECT lock on a table means nobody can read from or write to the table.
Second attempt. Batch it crazy.
So we try something else. We batch our inserts and deletes. It could look something like this.
DECLARE @minId bigint;
DECLARE @maxId bigint;
SELECT @minId = MIN(ID), @maxId = MAX(ID) FROM dbo.TableB;
DECLARE @batchSize int = 1000;
WHILE @minId <= @maxId + @batchSize
BEGIN
BEGIN TRY
BEGIN TRAN
INSERT INTO dbo.TableA (c1, c2, c3,..,cN)
SELECT c1, c2, c3,..,cN FROM dbo.tableB
WHERE ID>=@minId AND ID<@minId + @batchSize;
DELETE dbo.TableB WHERE ID>=@minId AND ID<@minId + @batchSize;
SET @minId = @minId + @batchSize;
COMMIT;
END TRY
BEGIN CATCH
IF @@TRANCOUNT > 0
ROLLBACK;
THROW;
END CATCH
END
What we have done now is to batch our inserts and deletes into batches of 1.000 rows. 1.000 rows wasn’t randomly selected. You read up on lock escalation and learned that lock escalation happens at certain thresholds. Some of these thresholds are really hard to predics, as they have to do with percentage of the lock manager’s memory. But you read that 5.000 is the magic number. When a transaction holds 5.000 locks on an object, lock escalation is triggered. So you decide that 1.000 rows should be a safe batchsize.
So you start running the above piece of code, and you still see a lot of blocking in the database. Why? How can this happen, you think to yourself. You let the code run for a bit, because you have been a responsible database developer and you run in a test environment where you have simulated the load from the application that hammers dbo.TableA with inserts, so that you won’t hurt users while you’re developing your solution. Well done!
So you read up on locks, and you learn that you can query sys.dm_tran_locks. You do that, and you filter on the session-id that runs the INSERT/DELETE-loop. After investigating what you can find from sys.dm_tran_locks, you end up with this query:
declare @sessionid int=56 --session-id of the SSMS-window that runs the INSERT/DELETE-loop
select count(*),resource_type,request_type,request_mode
from sys.dm_tran_locks
where request_session_id=@sessionid
group by resource_type,request_type,request_mode
You see that you have a lot of locks with resource_type=PAGE and request_mode=X. This means you have exclusive locks on PAGE level. What happens when your INSERT/DELETE-loop executes is that it will sooner or later allocate new pages. It will place an exclusive lock on those new pages. And since your simulated application workload hammer dbo.TableA with inserts, they get blocked by your INSERT/DELETE loop. And evere once in a while, the queued up inserts from your simulated workload will sneak in and write a row, and your INSERT/DELETE loop will have to wait for them to finish before it can go ahead and place new exclusive page locks on the table. And while your INSERT/DELETE loop wait to aquire these locks, new insert-attempts from your simulated workload will be placed in a queue behind your loop, etc, etc, etc.
Third and final attempt. Give the lock manager something to work with.
This is where ROWLOCK comes into play. I’m usually hesitant to use ROWLOCK hints on queries, because I don’t want to stress the lock manager with too many locks. But in this situation, it’s exactly what we want to do. We want to place fine-grained locks on row-level instead of PAGE-locks. When we need to allocate a new page, we don’t want our loop to set an exclusive lock ont the page. Instead, we want to set exclusive locks only on the rows it inserts into dbo.TableA.
So our final INSERT/DELETE-loop will look a little something like this.
DECLARE @minId bigint;
DECLARE @maxId bigint;
SELECT @minId = MIN(ID), @maxId = MAX(ID) FROM dbo.TableB;
DECLARE @batchSize int = 1000;
WHILE @minId <= @maxId + @batchSize
BEGIN
BEGIN TRY
BEGIN TRAN
INSERT INTO dbo.TableA WITH(ROWLOCK) (c1, c2, c3,..,cN)
SELECT c1, c2, c3,..,cN FROM dbo.tableB
WHERE ID>=@minId AND ID<@minId + @batchSize;
DELETE dbo.TableB WHERE ID>=@minId AND ID<@minId + @batchSize;
SET @minId = @minId + @batchSize;
COMMIT;
END TRY
BEGIN CATCH
IF @@TRANCOUNT > 0
ROLLBACK;
THROW;
END CATCH
END
Now you don’t see massive blocking anymore. And when you query sys.dm_tran_locks, the only X locks you see are with resource_type=KEY, meaning rowlocks.
Final words
Now you can start playing with the batchsize parameter. If you set it to a too high value, lock escalation to OBJECT level will happen and you will see massive blocking again. Remember that also indexes on the table need locks, and since you used a ROWLOCK-hint, there will be a KEY-lock per row that you inserted in the index. Lock escalation happens for individual objects, meaning if you have 3.000 key locks on the clustered index and another 3.000 key locks on a nonclustered index, lock escalation won’t kick in because of the 5.000 key threshold. Lock escalation happens when you have reached the threshold for a single object. But the more indexes you have on your table, the more memory will be consumed by the lock manager and chances are you will end up with lock escalation because you pushed the lock manager over a memory threshold instead.
To be more sure you pick the right batchsize before you move on to run your batch in production, make sure to test with a realistic workload, on an instance that has the same CPU and memory specs as your production server. If you don’t have such test rig, stay conservative with your batchsize.
I want to describe a secure way to pass a string-parameter containing a comma-separated list of column names to include in a result set. This can be useful when you’re often querying the same tables with the same predicates, but wish to include different columns in the result set for different purposes.
To setup our example, we’re going to use two tables in the AdventureWorks2022 database and the two tables Sales.SalesOrderHeader and Sales.SalesOrderDetail.
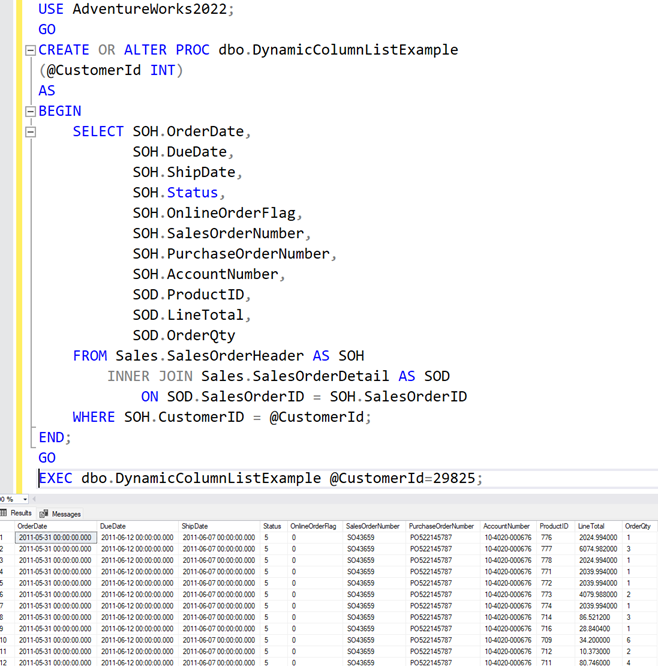
Our first version of the Stored Procedure has a fixed column list, so no dynamic columns in the result set.
Version 1 of our Stored Procedure
As you can see, we now have a stored procedure that returns some information about orders and line details.
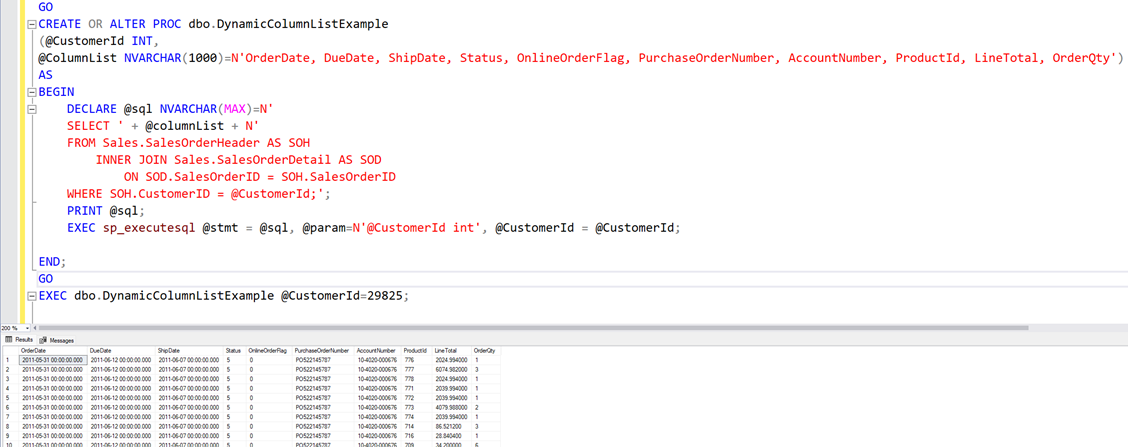
Moving on, we now want to change this stored procedure, so that it can return a more dynamic column list. Perhaps some parts of an application isn’t interested in Totals at all, and other parts of an application isn’t interested in DueDate or ShipDate at all, but the query apart from that more or less the same.
Let’s start with an example of how NOT to do it. First the code, and then I will show why the below is really bad idea.
Some dynamic SQL to take care of dynamic column list.
Although this works, sort of it opens up our database for SQL injection.
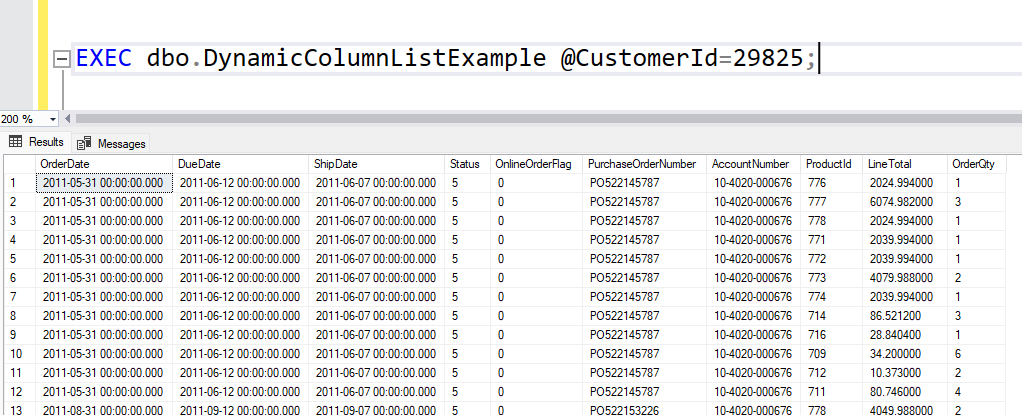
it will indeed give us the desired result set, with three columns.
But we can also do this.
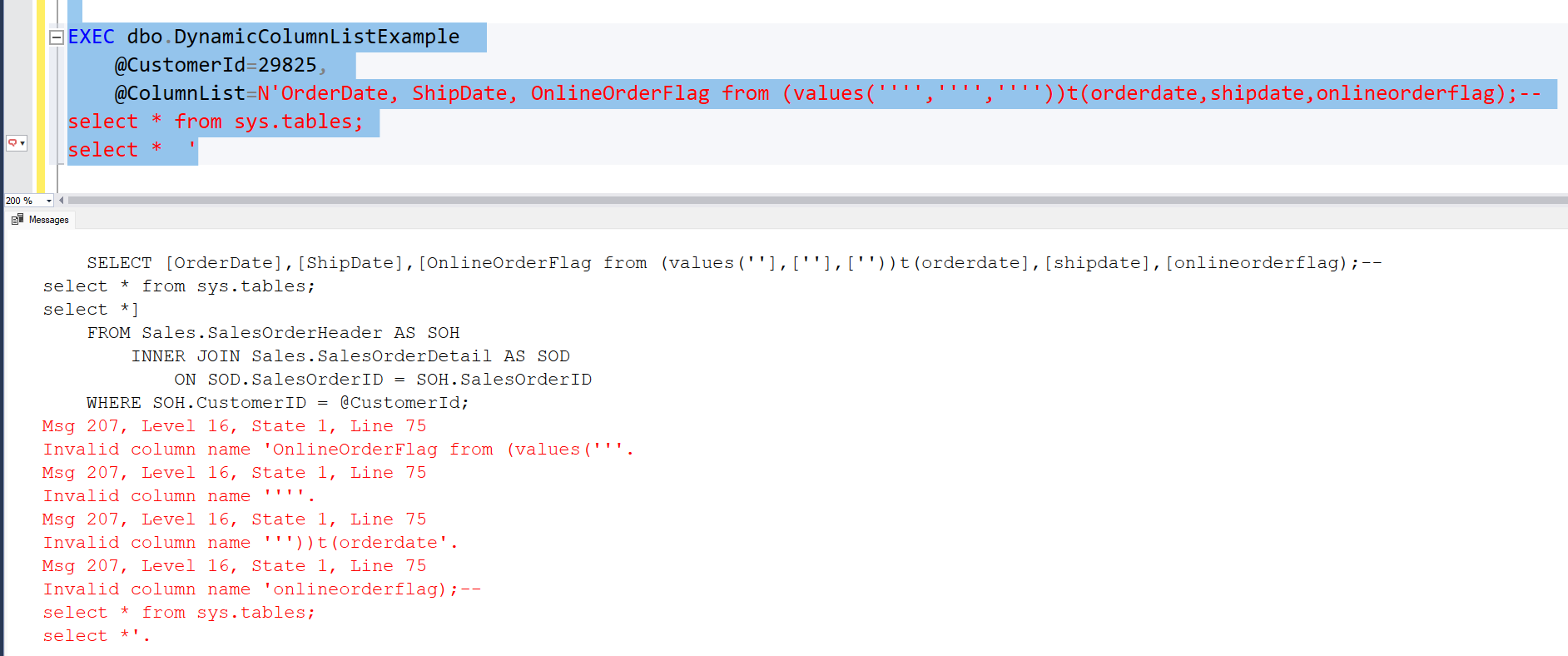
EXEC dbo.DynamicColumnListExample @CustomerId=29825, @ColumnList=N'OrderDate, ShipDate, OnlineOrderFlag from (values('''','''',''''))t(orderdate,shipdate,onlineorderflag);--
select * from sys.tables;
select * '
Wait, what???!!!
This will generate the following SQL-statements and the Stored Procedure will happily execute them with sp_executesql.
SELECT OrderDate, ShipDate, OnlineOrderFlag from (values('','',''))t(orderdate,shipdate,onlineorderflag);--
select * from sys.tables;
select *
FROM Sales.SalesOrderHeader AS SOH
INNER JOIN Sales.SalesOrderDetail AS SOD
ON SOD.SalesOrderID = SOH.SalesOrderID
WHERE SOH.CustomerID = @CustomerId;
So first a result set with three empty strings.
Then all the rows from sys.tables.
And finally all the columns from Sales.SalesOrderHeader and Sales.SalesOrderDetail for a given customer. Not at all what we were looking for, right?
But what if we still want to allow for dynamic column lists? We DO want to use dynamic SQL. But we can’t really do it this way. The way to secure this is to use the STRING_SPLIT function to convert the ColumnList parameter to a data set, and then convert it back to a comma separated list with STRING_AGG, but apply the QUOTENAME function to each element. Like this:
DECLARE @columnListSecure NVARCHAR(MAX);
SELECT @columNListSecure = STRING_AGG(QUOTENAME(TRIM(BOTH ' ' FROM value)),',')
FROM STRING_SPLIT(@ColumnList,',') AS SS
And then we use columnListSecure instead of columnList to build our column list in the dynamic SQL-statement.
Our final procedure looks like this:
CREATE OR ALTER PROC dbo.DynamicColumnListExample
(
@CustomerId INT,
@ColumnList NVARCHAR(1000) = N'OrderDate, DueDate, ShipDate, Status, OnlineOrderFlag, PurchaseOrderNumber, AccountNumber, ProductId, LineTotal, OrderQty'
)
AS
BEGIN
DECLARE @columnListSecure NVARCHAR(MAX);
SELECT @columnListSecure = STRING_AGG(QUOTENAME(TRIM(BOTH ' ' FROM value)), ',')
FROM STRING_SPLIT(@ColumnList, ',') AS SS;
DECLARE @sql NVARCHAR(MAX)
= N'
SELECT ' + @columnListSecure
+ N'
FROM Sales.SalesOrderHeader AS SOH
INNER JOIN Sales.SalesOrderDetail AS SOD
ON SOD.SalesOrderID = SOH.SalesOrderID
WHERE SOH.CustomerID = @CustomerId;';
PRINT @sql;
EXEC sp_executesql @stmt = @sql,
@param = N'@CustomerId int',
@CustomerId = @CustomerId;
END;
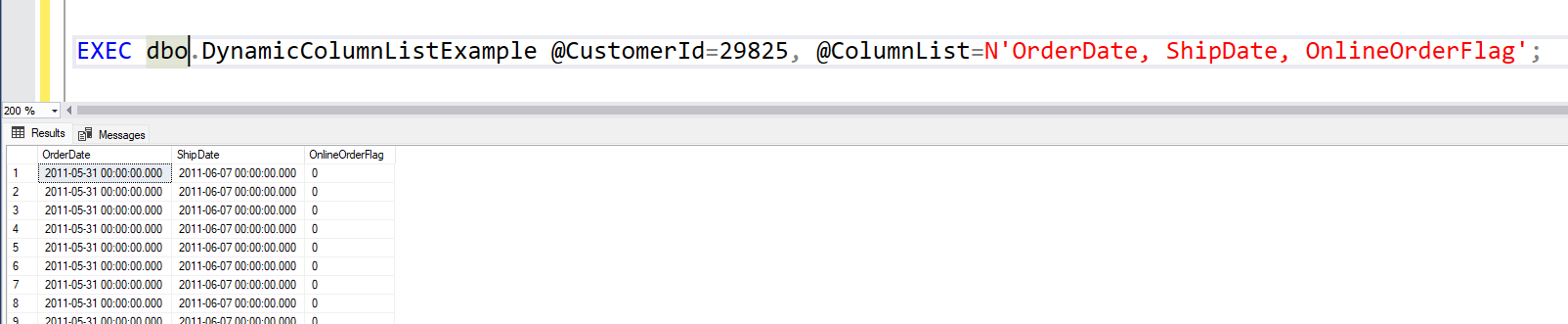
Let’s test it. First without a column list. Then using a column list with good intentions. And finally a column list with bad intentions.
Works like beforeAlso works like beforeHaha evil hacker, here are a couple of error messages for you!
As you can see from the printed SQL-statement, all the column identifiers are quoted and the error messages we get are that there are no columns named “OnlineOrderFlag from (values(”” etc. Meaning all the malicious code that was sent into the column list is translated to quoted identifiers which when used as part of our column list gives error messages. So we stopped an attacker from using a dynamic SQL injection vulnerability.
As a security-aware developer, you want the application services to be able to do exactly what they are supposed to do. Not more, not less. To test this, you can impersonate a login and see that the login has exactly the permissions you intend for it to have.
This is done using either execute as login or execute as user. In this post, I will show a few use cases for execute as user.
Let’s start with an example where we test the permissions for a given SQL Server Table.
-- Setup the database user. I'm testing with a user without login here.
CREATE USER PermTest WITHOUT LOGIN;
-- Create a Customer Table
CREATE TABLE dbo.Customer(
CustomerId int identity(1,1) CONSTRAINT PK_Customer PRIMARY KEY CLUSTERED,
CustomerName nvarchar(100) NOT NULL,
CustomerRegion nvarchar(100) NOT NULL,
CustomerRating tinyint CONSTRAINT DF_Customer_CustomerRating DEFAULT (3),
CONSTRAINT CK_Customer_CustomerRating_1_to_5 CHECK (CustomerRating >0 and CustomerRating <6)
) WITH (DATA_COMPRESSION=PAGE);
-- Give PermTest permission to read columns CustomerId, CustomerName and CustomerRegion but not CustomerRating
-- Now we test permissions, with EXECUTE AS
EXECUTE AS USER='PermTest';
-- Test that PermTest can't read all columns
SELECT * FROM dbo.Customer;
-- Test that PermTest can read the columns it should be able to read.
SELECT
CustomerId,
CustomerName,
CustomerRegion
FROM dbo.Customer;
-- Test if permissions can be "fooled"
SELECT CustomerId
FROM dbo.Customer
WHERE CustomerRating = 2;
REVERT;
Lines 14 and 27 is where the “magic” happens. Or rather where impersonation starts and stops. With EXECUTE AS USER=’PermTest’, our session impersonates the PermTest user and with the REVERT command, we switch back to our logged in user context.
The first test case will fail. The second will succeed and the third will fail.
Now let’s complicate things with some row-level security.
CREATE SCHEMA Security;
GO
-- Create the security predicate function
CREATE OR ALTER FUNCTION Security.UserRLSPredicate(@User as nvarchar(100))
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN SELECT 1 as RLSPredicateResult
WHERE @User = USER_NAME() OR USER_NAME()='dbo'
GO
-- Apply the security predicate using a security policy on table dbo.Customer
CREATE SECURITY POLICY RLSCustomerSalesRep
ADD FILTER PREDICATE Security.UserRLSPredicate(SalesRep)
ON dbo.Customer
WITH(STATE=ON);
GO
-- Finally we GRANT SELECT on the whole table to PermTest. The user should now see the rating, but only for their own customers.
-- First REVOKE existing permissions and then add only what we need.
REVOKE SELECT ON dbo.Customer TO PermTest;
GRANT SELECT ON dbo.Customer TO PermTest;
-- Now test if I as db_owner can see everything
SELECT * FROM dbo.Customer;
-- And finally test that Row Level Security predicate works
EXECUTE AS USER='PermTest'
SELECT * FROM dbo.Customer;
REVERT
These are some simple test cases using EXECUTE AS. They are somewhat silly, especially the predicate function – it should probably use metadata stored in tables instead of going straight at SalesRep = user-name. But that’s for you to figure out in your application. Using EXECUTE AS, you’re at least able to test if your permission structure works or not.
Final words: Don’t just give service accounts db_datareader, db_datawriter and EXECUTE (or even worse, db_owner) permissions. Unless that’s exactly what the service needs to be able to do. Give your service accounts just the right permissions, and test your security. A more advanced topic is to create stored procedures to elevate permissions for specific tasks, but that’s a bigger topic. One that Erland Sommarskog has written plenty about: Packaging Permissions in Stored Procedures (sommarskog.se)
In part 1 I showed in a video how to create a new, temporal table for row versioning in Sql Server. In this post, I will show how to convert an existing table to a system versioned (temporal) table.
CREATE TABLE dbo.PriceList(
ProductID INT NOT NULL CONSTRAINT PK_PriceList PRIMARY KEY CLUSTERED,
ListPrice MONEY NOT NULL
);
INSERT INTO dbo.PriceList (ProductID, ListPrice)
VALUES
(1,10),
(2,11),
(3,12);
We start with this small table, same as we used in part 1. Only this table already contains data. Same principles apply to existing tables, we need to add the two columns for start- and end-dates.
So we could try this.
ALTER TABLE dbo.PriceList ADD
RowStart DATETIME2(7) GENERATED ALWAYS AS ROW START,
RowEnd DATETIME2(7) GENERATED ALWAYS AS ROW END,
PERIOD FOR SYSTEM_TIME(RowStart, RowEnd);
But that gives us this result
Msg 4901, Level 16, State 1, Line 12
ALTER TABLE only allows columns to be added that can contain nulls, or have a DEFAULT definition specified, or the column being added is an identity or timestamp column, or alternatively if none of the previous conditions are satisfied the table must be empty to allow addition of this column. Column 'RowStart' cannot be added to non-empty table 'PriceList' because it does not satisfy these conditions.
So we can do this different ways. We could add the columns as normal columns, set values to them and then decorate them with “Generated always”. Instead, I’m going to add two default-constraints to the columns. RowStart can be set to whatever you find suitable. Current date and time perhaps? I’m going with 1900-01-01, to indicate the actual start-date is unknown.
ALTER TABLE dbo.PriceList ADD
RowStart DATETIME2(7) GENERATED ALWAYS AS ROW START CONSTRAINT DF_PriceList_RowStart DEFAULT '1900-01-01',
RowEnd DATETIME2(7) GENERATED ALWAYS AS ROW END CONSTRAINT DF_PriceList_RowEnd DEFAULT '9999-12-31 23:59:59.9999999',
PERIOD FOR SYSTEM_TIME(RowStart, RowEnd);
More important than the value for RowStart is the value for RowEnd. It has to be the max available value for the data-type. Since I’m using datetime2 with a high resolution, I need to set the date with seven decimals (three for milliseconds, three for microseconds and 1 for 100 nanoseconds).
Now I have prepared the table for system versioning. All that’s left to do is to alter the table to make it system versioned.
ALTER TABLE dbo.PriceList SET (SYSTEM_VERSIONING=ON(HISTORY_TABLE=dbo.PriceList_History));
And now, if we want to, we can drop the default constraints. They are kind of redundant, since the columns are decorated with Generated Always.
ALTER TABLE dbo.PriceList DROP CONSTRAINT DF_PriceList_RowStart;
ALTER TABLE dbo.PriceList DROP CONSTRAINT DF_PriceList_RowEnd;
And finally, let’s change values in the main table.
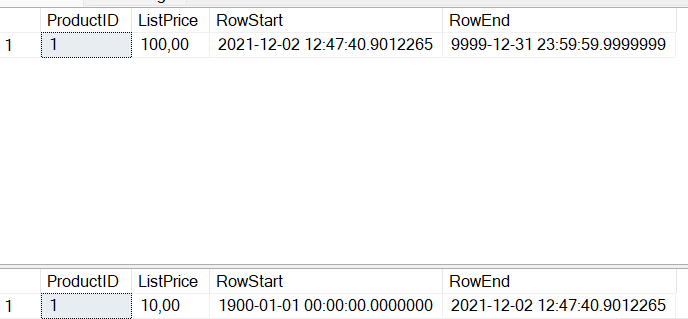
UPDATE dbo.PriceList SET ListPrice = 100 WHERE ProductID = 1;
If we now check the main table and the history table, we can see that the automatic row versioning is indeed in effect.
SELECT * FROM dbo.PriceList WHERE ProductID = 1;
SELECT * FROM dbo.PriceList_History WHERE ProductID = 1;
Done!
I hope you found this post useful. In part 3, we will look at how we can convert existing temporal pattern tables and make them automagically system versioned, temporal tables. That is: Tables where we have data in both a main table and a history table.
I’m working on a video series about Temporal Tables. In this first video I’m showing how to create a table which has System Versioning switched on. You might have heard the word Temporal Tables. What it means is that System Versioning is switched on for the table, and that all changes to the table are recorded in its history table.
Part 1 of my Temporal Tables video series.
In upcoming videos and blog posts, we’re going to look at some more complex scenarios, such as
Add system versioning to an existing table
Switch from home-cooked versioning to automatic system versioning
Use the FOR SYSTEM_TIME features in Transact-SQL
Performance considerations for temporal tables
Do you have any specific use cases for temporal tables that you want me to bring up in this series? Drop a comment here, or on the YouTube video, and we’ll see what we can do.
Today, I have another example of the usage of Tally Tables. I have used this approach many times, to generate a calendar dimension for a Data Warehouse. Or more often, when I need to do reporting with fixed periods (hourly, daily, weekly etc) but there’s no underlying data for some of the periods.
In the video, I show how the technique with generating variable length time slots work.
As in my previous post, I have finalised the code and made a function that you can use. It’s an inline table valued function, so you can join or cross apply to it without having to worry too much about performance issues with it. Having said that, cardinality estimation may or may not be a performance issue for you if you use this function to drive eg a report. Because SQL Server might make some funky assumptions about the number of rows returned from the query. But let’s first look at the code for the actual function.
CREATE FUNCTION dbo.GenerateTimeSlots(@Start DATETIME, @End DATETIME, @IntervalLengthSeconds INT)
RETURNS TABLE AS
RETURN(
WITH ten AS(
SELECT n FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),(1),(1)) t(n)
), millions AS (
SELECT
TOP(DATEDIFF(SECOND,@start,@end)/@IntervalLengthSeconds)
ROW_NUMBER() OVER(ORDER BY (SELECT 'no specific order')) AS n
FROM ten t1
CROSS JOIN ten t2
CROSS JOIN ten t3
CROSS JOIN ten t4
CROSS JOIN ten t5
CROSS JOIN ten t6
ORDER BY n
)SELECT
DATEADD(SECOND,@IntervalLengthSeconds * (n-1),@start) AS TimeSlotStart, n AS TimeSlotNumber
FROM millions);
Depending on how you call this function, you may or may not suffer from bad cardinality estimation. Let’s start with an example where SQL Server estimates cardinality properly
SELECT * FROM dbo.GenerateTimeSlots('2020-03-11',CURRENT_TIMESTAMP, 3600);
In the above call, SQL Server estimates 13255 rows to be returned from the query. Which turns out to be exactly right (depending on when you run it of course, since I’m using CURRENT_TIMESTAMP for the end-date).
Now, try calling the function with these lines of code.
DECLARE @IntervalLengthSeconds INT=3600;
SELECT * FROM dbo.GenerateTimeSlots('2020-03-11',CURRENT_TIMESTAMP,@IntervalLengthSeconds)
This time, SQL Server estimates 100 rows to be returned from the query. Which of course isn’t correct. It will still return 13255 rows. This is because SQL Server sees a variable for the @IntervalLengthSeconds parameter and doesn’t know the value of the parameter.
If you WILL use a variable for any of the parameters, and you know how many time slots you _most often_ will return from the query, you can make an adjustment to add your own estimation using the query hint OPTIMIZE FOR. Like this:
DECLARE @IntervalLengthSeconds INT=3600;
SELECT * FROM dbo.GenerateTimeSlots('2020-03-11',CURRENT_TIMESTAMP,@IntervalLengthSeconds)
OPTION(OPTIMIZE FOR(@IntervalLengthSeconds=3600));
In the above example, this of course looks a bit stupid, because I set the variable value to a constant and then optimize for the variable to have that value. It would be much easier to just call the function using that constant. But you might pull up that value from a table in a previous statement, and in that case, you can use this technique to force a certain value, for the cardinality estimation.
This is my first attempt at short Transact-SQL videos. I was answering a question on a SQL Server related Facebook group. The question was about generating four-letter codes containing all possible combinations of letters A-Z. There are 26 letters in the english alphabet. Meaning the T-SQL code should generate 26^4 rows, or 456,976 rows.
But I worked a bit further on the solution, and created a stored procedure which with parameters can create any length strings for the codes and also persist the data in a table instead of returning the rows to the caller.
What I’ve done is generate a string with SQL-code, based on the parameters, and then execute the SQL-code with the system stored procedure sys.sp_executesql.
CREATE OR ALTER PROC dbo.GenerateLetterStrings
(
@LetterCount TINYINT,
@ResultTable NVARCHAR(128) = NULL
)
AS
BEGIN
SET NOCOUNT ON;
DECLARE @sql NVARCHAR(MAX)
= N'
WITH alphabet AS (
SELECT CHAR(ASCII(''A'')+ ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) -1) AS n
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1)) t(n)
)SELECT
<<selectlist>> AS word
<<intoclause>>
FROM alphabet AS t0
<<crossjoin>>
' ;
DECLARE @SelectList NVARCHAR(MAX) = N't0.n',
@CrossJoin NVARCHAR(MAX) = N'';
WITH eight
AS (SELECT n
FROM
(
VALUES
(1),
(1),
(1),
(1),
(1),
(1),
(1),
(1)
) t (n) ),
twofiftysix
AS (SELECT TOP (@LetterCount - 1)
ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) AS n
FROM eight
CROSS JOIN eight e2
ORDER BY 1)
SELECT @CrossJoin = @CrossJoin + CONCAT('CROSS JOIN alphabet as t', n, '
'),
@SelectList = @SelectList + CONCAT('+t', n, '.n')
FROM twofiftysix;
SET @sql = REPLACE(@sql, N'<<selectlist>>', @SelectList);
SET @sql = REPLACE(@sql, N'<<crossjoin>>', @CrossJoin);
SET @sql = REPLACE(@sql, N'<<intoclause>>', COALESCE(N'INTO ' + @ResultTable, N''));
EXEC sys.sp_executesql @sql;
END;
This blog post is about an error message I got the other day when using DBCC CLONEDATABASE in a T-sql-script. But first some background to DBCC CLONEDATABASE.
I was pretty excited about the DBCC CLONEDATABASE command, which was introduced in SQL Server 2014 SP2 and SQL Server 2016 SP1. It creates a schema-only (that means all the database objects, but no data) copy of a database, keeping all statistics data, so that you can troubleshoot Query plans for certain queries without having to copy all the data. Before DBCC CLONEDATABASE (and to be honest probably also afterwords, DBCC CLONEDATABASE doesn’t replace all the needs) one had to make a full copy of a database to get the statistics data along. That’s usually copied to a test box. If the test box is identical to your production box, you’re almost fine. But on your test box, you don’t have the cached execution plans from the production box. Therefore, you might end up with very different Query plans in your test box. With DBCC CLONEDATABASE, you get a readonly copy of a database, on your production box and you can use that to tweak your queries and see what new estimated execution plans they get.
Many SQL Server developers and admins found, after upgrading to SQL Server 2014, that some queries started taking much longer time than before. The reason is the new cardinality estimation formula which was introduced in SQL Server 2014. Cardinality Estimation is done all the time by the SQL Server optimizer. To produce a Query plan, the optimizer makes some assumptions about how many rows exist for each condition in the table. In most cases, the new cardinality estimation formula in SQL Server 2014 and onwards gives slightly better estimates and the optimizer therefore produces slightly better plans. In some cases however, mostly when there are predicates on more than one column in a WHERE clause or JOIN clause, the 2014 cardinality estimation is a lot worse than in previous versions of SQL Server.