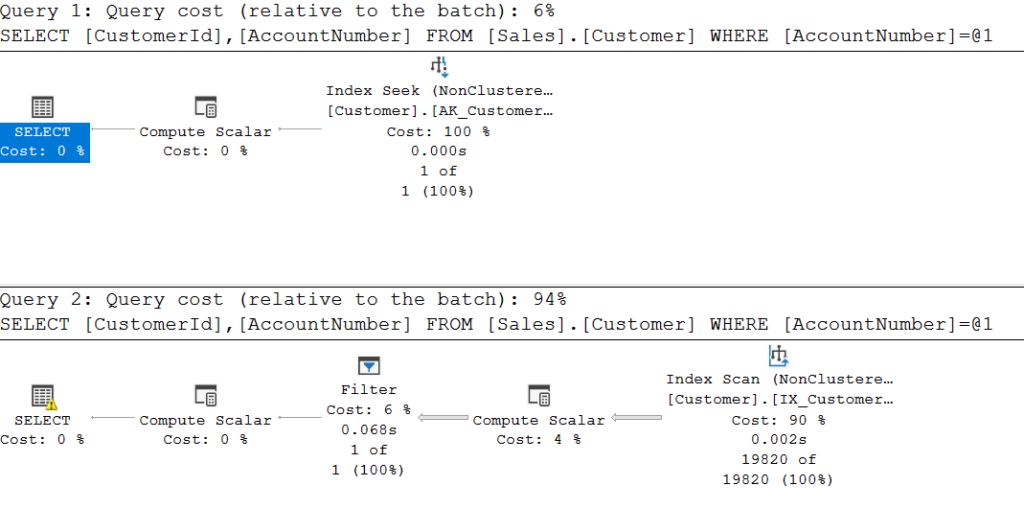
Background to this post: I’m writing this post assuming you haven’t enabled read committed snapshot on your database. You will find DBAs online who tell you to just do it – it will solve all your locking problems. This is not the case. read committed snapshot is wonderful sometimes. But it comes with a cost. It’s not a one-size-fits-all solution to your blocking problems.

The business problem to solve
Consider the following SQL Server situation. You have a table with the really innovative name dbo.TableA. dbo.TableA has an identity column as Primary Key (and clustered key). You have an application that hammers dbo.TableA with single row inserts 24/7. This application uses SCOPE_IDENTITY() to figure out what value the identity column got for a single inserted row. You can’t change the application. And you are now given the task to move one billion rows from dbo.TableB. No rows may exist in both dbo.TableA and dbo.TableB at the same time.
Since you have an application hammering dbo.TableA with inserts, and this application relies on SCOPE_IDENTITY() to find the identity value for inserted rows, you can’t change the table to use a sequence to get default values – you need the identity column to stay an identity column. And you need to insert one billion rows into the table without causing blocking for the application hammering dbo.TableA with inserts.
What’s good for you though is that you don’t need to keep the PK value from dbo.TableB when it’s inserted into dbo.TableA. This is a made-up business case, but I was tasked with something very similar recently, and that gave me the idea to write this blog post.
First attempt. The naive approach.
Your first attempt to solve this problem may be as simple as:
BEGIN TRAN
INSERT INTO dbo.TableA (c1, c2, c3,..,cN)
SELECT c1, c2, c3,..,CN) FROM dbo.TableB
DELETE dbo.TableB.
COMMIT
Looks easy, right? But we’re talking about billions of rows in dbo.TableB. And users will not be happy if you block dbo.TableA. And inserting billions of rows into a table will cause blocking. Why? Because this single insert will first set PAGE-locks. These PAGE-locks will be exclusive locks, meaning no other session can read from or write to the pages. And sooner rather than later, there will be so many locks from this transaction, that lock escalation will happen. Lock escalation is when a single transaction has created so many locks that SQL Server decides it’s getting a bit much to handle, and changes the PAGE-locks to OBJECT locks. OBJECT locks in this case means TABLE locks. An exclusive OBJECT lock on a table means nobody can read from or write to the table.
Second attempt. Batch it crazy.
So we try something else. We batch our inserts and deletes. It could look something like this.
DECLARE @minId bigint;
DECLARE @maxId bigint;
SELECT @minId = MIN(ID), @maxId = MAX(ID) FROM dbo.TableB;
DECLARE @batchSize int = 1000;
WHILE @minId <= @maxId + @batchSize
BEGIN
BEGIN TRY
BEGIN TRAN
INSERT INTO dbo.TableA (c1, c2, c3,..,cN)
SELECT c1, c2, c3,..,cN FROM dbo.tableB
WHERE ID>=@minId AND ID<@minId + @batchSize;
DELETE dbo.TableB WHERE ID>=@minId AND ID<@minId + @batchSize;
SET @minId = @minId + @batchSize;
COMMIT;
END TRY
BEGIN CATCH
IF @@TRANCOUNT > 0
ROLLBACK;
THROW;
END CATCH
END
What we have done now is to batch our inserts and deletes into batches of 1.000 rows. 1.000 rows wasn’t randomly selected. You read up on lock escalation and learned that lock escalation happens at certain thresholds. Some of these thresholds are really hard to predics, as they have to do with percentage of the lock manager’s memory. But you read that 5.000 is the magic number. When a transaction holds 5.000 locks on an object, lock escalation is triggered. So you decide that 1.000 rows should be a safe batchsize.
So you start running the above piece of code, and you still see a lot of blocking in the database. Why? How can this happen, you think to yourself. You let the code run for a bit, because you have been a responsible database developer and you run in a test environment where you have simulated the load from the application that hammers dbo.TableA with inserts, so that you won’t hurt users while you’re developing your solution. Well done!
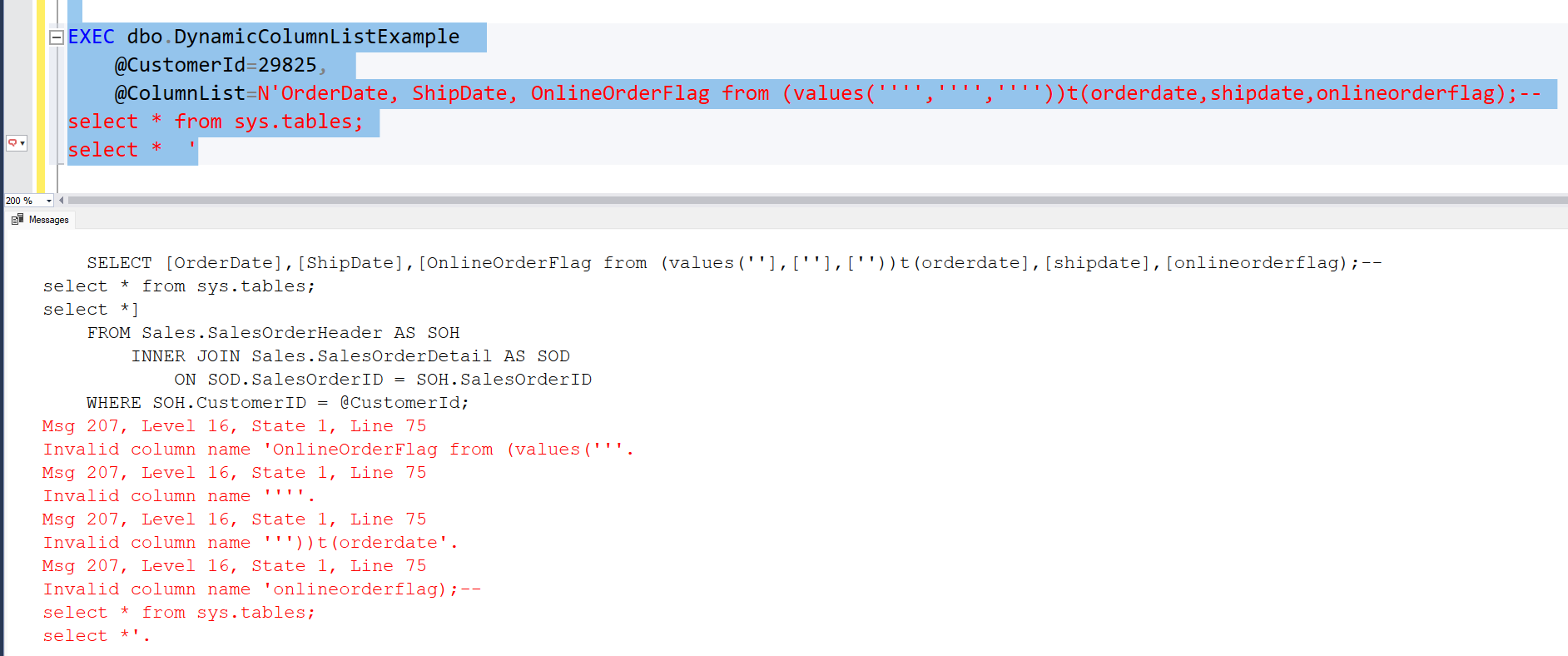
So you read up on locks, and you learn that you can query sys.dm_tran_locks. You do that, and you filter on the session-id that runs the INSERT/DELETE-loop. After investigating what you can find from sys.dm_tran_locks, you end up with this query:
declare @sessionid int=56 --session-id of the SSMS-window that runs the INSERT/DELETE-loop
select count(*),resource_type,request_type,request_mode
from sys.dm_tran_locks
where request_session_id=@sessionid
group by resource_type,request_type,request_mode
You see that you have a lot of locks with resource_type=PAGE and request_mode=X. This means you have exclusive locks on PAGE level. What happens when your INSERT/DELETE-loop executes is that it will sooner or later allocate new pages. It will place an exclusive lock on those new pages. And since your simulated application workload hammer dbo.TableA with inserts, they get blocked by your INSERT/DELETE loop. And evere once in a while, the queued up inserts from your simulated workload will sneak in and write a row, and your INSERT/DELETE loop will have to wait for them to finish before it can go ahead and place new exclusive page locks on the table. And while your INSERT/DELETE loop wait to aquire these locks, new insert-attempts from your simulated workload will be placed in a queue behind your loop, etc, etc, etc.
Third and final attempt. Give the lock manager something to work with.
This is where ROWLOCK comes into play. I’m usually hesitant to use ROWLOCK hints on queries, because I don’t want to stress the lock manager with too many locks. But in this situation, it’s exactly what we want to do. We want to place fine-grained locks on row-level instead of PAGE-locks. When we need to allocate a new page, we don’t want our loop to set an exclusive lock ont the page. Instead, we want to set exclusive locks only on the rows it inserts into dbo.TableA.
So our final INSERT/DELETE-loop will look a little something like this.
DECLARE @minId bigint;
DECLARE @maxId bigint;
SELECT @minId = MIN(ID), @maxId = MAX(ID) FROM dbo.TableB;
DECLARE @batchSize int = 1000;
WHILE @minId <= @maxId + @batchSize
BEGIN
BEGIN TRY
BEGIN TRAN
INSERT INTO dbo.TableA WITH(ROWLOCK) (c1, c2, c3,..,cN)
SELECT c1, c2, c3,..,cN FROM dbo.tableB
WHERE ID>=@minId AND ID<@minId + @batchSize;
DELETE dbo.TableB WHERE ID>=@minId AND ID<@minId + @batchSize;
SET @minId = @minId + @batchSize;
COMMIT;
END TRY
BEGIN CATCH
IF @@TRANCOUNT > 0
ROLLBACK;
THROW;
END CATCH
END
Now you don’t see massive blocking anymore. And when you query sys.dm_tran_locks, the only X locks you see are with resource_type=KEY, meaning rowlocks.
Final words
Now you can start playing with the batchsize parameter. If you set it to a too high value, lock escalation to OBJECT level will happen and you will see massive blocking again. Remember that also indexes on the table need locks, and since you used a ROWLOCK-hint, there will be a KEY-lock per row that you inserted in the index. Lock escalation happens for individual objects, meaning if you have 3.000 key locks on the clustered index and another 3.000 key locks on a nonclustered index, lock escalation won’t kick in because of the 5.000 key threshold. Lock escalation happens when you have reached the threshold for a single object. But the more indexes you have on your table, the more memory will be consumed by the lock manager and chances are you will end up with lock escalation because you pushed the lock manager over a memory threshold instead.
To be more sure you pick the right batchsize before you move on to run your batch in production, make sure to test with a realistic workload, on an instance that has the same CPU and memory specs as your production server. If you don’t have such test rig, stay conservative with your batchsize.