In part 1 I showed in a video how to create a new, temporal table for row versioning in Sql Server. In this post, I will show how to convert an existing table to a system versioned (temporal) table.
CREATE TABLE dbo.PriceList(
ProductID INT NOT NULL CONSTRAINT PK_PriceList PRIMARY KEY CLUSTERED,
ListPrice MONEY NOT NULL
);
INSERT INTO dbo.PriceList (ProductID, ListPrice)
VALUES
(1,10),
(2,11),
(3,12);
We start with this small table, same as we used in part 1. Only this table already contains data. Same principles apply to existing tables, we need to add the two columns for start- and end-dates.
So we could try this.
ALTER TABLE dbo.PriceList ADD
RowStart DATETIME2(7) GENERATED ALWAYS AS ROW START,
RowEnd DATETIME2(7) GENERATED ALWAYS AS ROW END,
PERIOD FOR SYSTEM_TIME(RowStart, RowEnd);
But that gives us this result
Msg 4901, Level 16, State 1, Line 12
ALTER TABLE only allows columns to be added that can contain nulls, or have a DEFAULT definition specified, or the column being added is an identity or timestamp column, or alternatively if none of the previous conditions are satisfied the table must be empty to allow addition of this column. Column 'RowStart' cannot be added to non-empty table 'PriceList' because it does not satisfy these conditions.
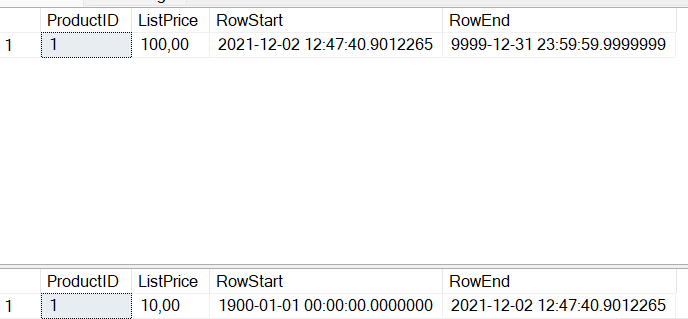
So we can do this different ways. We could add the columns as normal columns, set values to them and then decorate them with “Generated always”. Instead, I’m going to add two default-constraints to the columns. RowStart can be set to whatever you find suitable. Current date and time perhaps? I’m going with 1900-01-01, to indicate the actual start-date is unknown.
ALTER TABLE dbo.PriceList ADD
RowStart DATETIME2(7) GENERATED ALWAYS AS ROW START CONSTRAINT DF_PriceList_RowStart DEFAULT '1900-01-01',
RowEnd DATETIME2(7) GENERATED ALWAYS AS ROW END CONSTRAINT DF_PriceList_RowEnd DEFAULT '9999-12-31 23:59:59.9999999',
PERIOD FOR SYSTEM_TIME(RowStart, RowEnd);
More important than the value for RowStart is the value for RowEnd. It has to be the max available value for the data-type. Since I’m using datetime2 with a high resolution, I need to set the date with seven decimals (three for milliseconds, three for microseconds and 1 for 100 nanoseconds).
Now I have prepared the table for system versioning. All that’s left to do is to alter the table to make it system versioned.
ALTER TABLE dbo.PriceList SET (SYSTEM_VERSIONING=ON(HISTORY_TABLE=dbo.PriceList_History));
And now, if we want to, we can drop the default constraints. They are kind of redundant, since the columns are decorated with Generated Always.
ALTER TABLE dbo.PriceList DROP CONSTRAINT DF_PriceList_RowStart;
ALTER TABLE dbo.PriceList DROP CONSTRAINT DF_PriceList_RowEnd;
And finally, let’s change values in the main table.
UPDATE dbo.PriceList SET ListPrice = 100 WHERE ProductID = 1;
If we now check the main table and the history table, we can see that the automatic row versioning is indeed in effect.
SELECT * FROM dbo.PriceList WHERE ProductID = 1;
SELECT * FROM dbo.PriceList_History WHERE ProductID = 1;
Done!
I hope you found this post useful. In part 3, we will look at how we can convert existing temporal pattern tables and make them automagically system versioned, temporal tables. That is: Tables where we have data in both a main table and a history table.
I’m working on a video series about Temporal Tables. In this first video I’m showing how to create a table which has System Versioning switched on. You might have heard the word Temporal Tables. What it means is that System Versioning is switched on for the table, and that all changes to the table are recorded in its history table.
Part 1 of my Temporal Tables video series.
In upcoming videos and blog posts, we’re going to look at some more complex scenarios, such as
Add system versioning to an existing table
Switch from home-cooked versioning to automatic system versioning
Use the FOR SYSTEM_TIME features in Transact-SQL
Performance considerations for temporal tables
Do you have any specific use cases for temporal tables that you want me to bring up in this series? Drop a comment here, or on the YouTube video, and we’ll see what we can do.
Today, I have another example of the usage of Tally Tables. I have used this approach many times, to generate a calendar dimension for a Data Warehouse. Or more often, when I need to do reporting with fixed periods (hourly, daily, weekly etc) but there’s no underlying data for some of the periods.
In the video, I show how the technique with generating variable length time slots work.
As in my previous post, I have finalised the code and made a function that you can use. It’s an inline table valued function, so you can join or cross apply to it without having to worry too much about performance issues with it. Having said that, cardinality estimation may or may not be a performance issue for you if you use this function to drive eg a report. Because SQL Server might make some funky assumptions about the number of rows returned from the query. But let’s first look at the code for the actual function.
CREATE FUNCTION dbo.GenerateTimeSlots(@Start DATETIME, @End DATETIME, @IntervalLengthSeconds INT)
RETURNS TABLE AS
RETURN(
WITH ten AS(
SELECT n FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),(1),(1)) t(n)
), millions AS (
SELECT
TOP(DATEDIFF(SECOND,@start,@end)/@IntervalLengthSeconds)
ROW_NUMBER() OVER(ORDER BY (SELECT 'no specific order')) AS n
FROM ten t1
CROSS JOIN ten t2
CROSS JOIN ten t3
CROSS JOIN ten t4
CROSS JOIN ten t5
CROSS JOIN ten t6
ORDER BY n
)SELECT
DATEADD(SECOND,@IntervalLengthSeconds * (n-1),@start) AS TimeSlotStart, n AS TimeSlotNumber
FROM millions);
Depending on how you call this function, you may or may not suffer from bad cardinality estimation. Let’s start with an example where SQL Server estimates cardinality properly
SELECT * FROM dbo.GenerateTimeSlots('2020-03-11',CURRENT_TIMESTAMP, 3600);
In the above call, SQL Server estimates 13255 rows to be returned from the query. Which turns out to be exactly right (depending on when you run it of course, since I’m using CURRENT_TIMESTAMP for the end-date).
Now, try calling the function with these lines of code.
DECLARE @IntervalLengthSeconds INT=3600;
SELECT * FROM dbo.GenerateTimeSlots('2020-03-11',CURRENT_TIMESTAMP,@IntervalLengthSeconds)
This time, SQL Server estimates 100 rows to be returned from the query. Which of course isn’t correct. It will still return 13255 rows. This is because SQL Server sees a variable for the @IntervalLengthSeconds parameter and doesn’t know the value of the parameter.
If you WILL use a variable for any of the parameters, and you know how many time slots you _most often_ will return from the query, you can make an adjustment to add your own estimation using the query hint OPTIMIZE FOR. Like this:
DECLARE @IntervalLengthSeconds INT=3600;
SELECT * FROM dbo.GenerateTimeSlots('2020-03-11',CURRENT_TIMESTAMP,@IntervalLengthSeconds)
OPTION(OPTIMIZE FOR(@IntervalLengthSeconds=3600));
In the above example, this of course looks a bit stupid, because I set the variable value to a constant and then optimize for the variable to have that value. It would be much easier to just call the function using that constant. But you might pull up that value from a table in a previous statement, and in that case, you can use this technique to force a certain value, for the cardinality estimation.
This is my first attempt at short Transact-SQL videos. I was answering a question on a SQL Server related Facebook group. The question was about generating four-letter codes containing all possible combinations of letters A-Z. There are 26 letters in the english alphabet. Meaning the T-SQL code should generate 26^4 rows, or 456,976 rows.
But I worked a bit further on the solution, and created a stored procedure which with parameters can create any length strings for the codes and also persist the data in a table instead of returning the rows to the caller.
What I’ve done is generate a string with SQL-code, based on the parameters, and then execute the SQL-code with the system stored procedure sys.sp_executesql.
CREATE OR ALTER PROC dbo.GenerateLetterStrings
(
@LetterCount TINYINT,
@ResultTable NVARCHAR(128) = NULL
)
AS
BEGIN
SET NOCOUNT ON;
DECLARE @sql NVARCHAR(MAX)
= N'
WITH alphabet AS (
SELECT CHAR(ASCII(''A'')+ ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) -1) AS n
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1)) t(n)
)SELECT
<<selectlist>> AS word
<<intoclause>>
FROM alphabet AS t0
<<crossjoin>>
' ;
DECLARE @SelectList NVARCHAR(MAX) = N't0.n',
@CrossJoin NVARCHAR(MAX) = N'';
WITH eight
AS (SELECT n
FROM
(
VALUES
(1),
(1),
(1),
(1),
(1),
(1),
(1),
(1)
) t (n) ),
twofiftysix
AS (SELECT TOP (@LetterCount - 1)
ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) AS n
FROM eight
CROSS JOIN eight e2
ORDER BY 1)
SELECT @CrossJoin = @CrossJoin + CONCAT('CROSS JOIN alphabet as t', n, '
'),
@SelectList = @SelectList + CONCAT('+t', n, '.n')
FROM twofiftysix;
SET @sql = REPLACE(@sql, N'<<selectlist>>', @SelectList);
SET @sql = REPLACE(@sql, N'<<crossjoin>>', @CrossJoin);
SET @sql = REPLACE(@sql, N'<<intoclause>>', COALESCE(N'INTO ' + @ResultTable, N''));
EXEC sys.sp_executesql @sql;
END;
I’m trying to summarise 2020. Don’t know how to describe the year. It’s been…. rich in content.
This post will be slightly unstructured as I’ve tried to write down just the things
Picture: mr_write at morguefile.com
New Year, New Opportunities
2020 started pretty normal. After some time off with the family, I started a new, one-year consultant assignment with the company I was employed at before I started my company. Though I had been away for some years, it was nice to be back. A lot had changed, but even more was the same. Most of all, it was nice to catch up with some very awesome people that I hadn’t seen for a couple of years.
I had set out to visit more SQL Saturdays and other conferences than previous years, and I started with a trip to SQL Saturday Vienna on January 24th (yes, that’s a Friday, the Austrians don’t know their weekdays like the rest of us😊).
Covid-19
I’m not sure when we first heard about Covid-19, but it can’t have been long after SQL Saturday Vienna. It started as something in China. Then there were some travel restrictions and before we knew it, several european countries were reporting the virus spreading out of control.
In my team at work, key people were sent home to work from home, to make sure we could maintain operations if the virus took out the whole office. Within two weeks, the rest of us were sent home. This must have been by the end of March. Initially, we were meant to work from home for a few months, perhaps until summer vacations. And when people came back from summer vacations, the word was that we would be slowly moving back to working in the office instead of working from home. And then came the second wave.
Since end of March, I haven’t set foot in my client’s office. Instead, I rented a small office room in my home town, early November so that I wouldn’t have to spend afternoons with “daddy is in a meeting, please keep your voice down” to my kids. After all, the house is there home more than it was my office. It feels nice to leave the house and go to the office. There are a few more persons on the office floor where I rent my room, on a busy day there are as many as four or five. We keep the distance, and I work with the door to my room closed, so it feels safe.
This pandemic will be over at one point. We don’t yet know when. Vaccine is being distributed as I write, but it will take months before enough people get the vaccine before we can relax.
I think this pandemic and the timing of it will change the way many of us work. Obviously, some jobs can’t be done remotely. Teaching and learning will be mainly an in-person activity. Construction workers, nurses and doctors can’t work from home. But for all of us that CAN work from a remote location, I think the “new normal” will be remote work, with fixed days when we meet in a common location. At least I’m not ready to go back to spending 12,5 hours per week commuting anytime soon.
One year working with this client has been really amazing and I’m happy to have signed a contract for 2021 as well. It’s been a tremendous team work, when we have migrated lots of systems to new infrastructure, with the goal of improving documentation and become more cloud-ready with the applications. I have become more fluent with Powershell and I have learned a lot about networking, DNS and load balancers than I anticipated. And of course, I have tuned a SQL statement or two. After all, DBA is my main reponsibility within the team.
Data Weekender
With SQL Saturdays cancelled or postponed, there was a vacuum in the Data Community. Speakers didn’t have conferences to attend and data professionals had far less learning and networking opportunities when countries went into lockdown mode. I responded to a tweet from Kevin Chant, where he asked if anyone was interested in trying to organise a virtual conference. Damir Matesic, Gethyn Ellis, Asgeir Gunnarsson and Mark Hayes also replied to Kevin’s tweet.
We had a first zoom meeting to discuss the format of a virtual conference. Mark did some magic with a cool picture from Kevin’s honey moon, where he was sitting in a camper van, and we decided the name of the conference would be Data Community Weekender Europe (which was later changed to just Data Weekender). https://www.dataweekender.com
On this first zoom-call, we also decided on the date for the first edition of Data Weekender. And looking back, I can totally see how unrealistic it was. We were to organise a conference within 30 days, and all we had was a name and a cool picture.
But we did it. We opened up the Call for Speakers and left it open for only ten days, April 8 – April 17. We organised Data Weekender on a zero budget, which meant we didn’t have a marketing budget. Instead, we relied on Twitter and LinkedIn to spread the word. And it worked! We anticipated a conference with two or three tracks but we got 196 submissions from 76 individual speakers and ended up running the conference on six tracks with a total of 42 sessions.
The first edition of Data Weekender was May 2nd and we had roughly 600 individuals participating in the conference.
On October 17th, we did #DataWeekender #TheSQL, with a few more sessions and with some lightning talks. More or less the same number of participants, which we think was a pretty good result, as by then, there were many, many more virtual events being organised.
Thank you Kevin, Damir, Gethyn, Asgeir and Mark! I look forward to The Van running again in 2021!
SQL Friday
Just after the first edition of Data Weekender, I went public with my idea to run a weekly online lunch event, SQL Friday (https://sqlfriday.net) . I didn’t publish a Call for Speakers for the whole season, but instead made sure I had speakers for the first few weeks, started tweeting about it and hoped for the best.
And it worked out pretty well. Sql Friday episode #1 had Damir Matesic as the guest star. The topic was T-SQL and JSON and it had 120 registered attendees.
The format of SQL Friday is casual. There’s no powerpoint template. There are no sponsors to thank (my company is organising the event and people participating is enough thanks) and speakers can choose to do 60 minutes of demos or 60 minutes of just powerpoint slides. It’s all up to the speaker.
There have been a couple of “bloopers” this season, and I’m sure we will have more of them in 2021. When Mark Hayes had some problems with his audio, I told him for a minute or two that we could now hear him, while he was changing settings. But I was muted, so he didn’t hear me. But the worst one was probably when Gianluca Sartori got a blue screen in the middle of a demo. “Gianluca, hello, are you there?”. But he was back on the call within five minutes and continued like nothing happened. Impressive!
I want to thank all the speakers and attendees for joining me for 29 fridays in 2020. The schedule for January-June 2021 is published and we have 25 really good sessions to look forward to, the first one being on January 8. If you haven’t already, join the Meetup group at https://meetup.com/sql-friday.
SQL User Group activity
With in-person events out of the question, SQL Server Usergroup Sweden went virtual, as did many other groups. And we’re still virtual, at least for the coming few months. Lately, we have started having bi-weekly user group meetings, even when there are no speakers. We just meet and have a chat about work and personal life. It’s nice to see some familiar faces and get that important networking going.
Public speaking
With in-person events cancelled, I have had more opportunities to speak at events and user groups I wouldn’t have been able to visit otherwise. For example, I did a talk about dbatools for the Quad City User Group in April, and another one about partitioning for the PASS380-group, the day before. It was middle of the night for me, but I’m a night owl anyway so it was all right. I “went to” Singapore in the autumn and I spoke at Data Platform Summit in the winter. And I’ve done a few Virtual SQL Saturday talks as well.
In september, I did an in-person talk at SQL Saturday Gothenburg. There were not many attendees, I think Mikael who organised the event had set a limit of 50 attendees. But regardless the size of the event, it felt so, so good to be in a classroom and actually meet people, to be able to stay for an informal Q&A-session in the hallway after the talk, and to be able to hang out in the hotel bar with Asgeir Gunnarsson and Erland Sommarskog in the evening.
MVP
I can’t summarize 2020 without mentioning I was awarded Microsoft Most Valuable Professional. I know a lot of MVPs say the same, but I was honestly not expecting this award. Thank you so much Damir Matesic for nominating me, and thank you Microsoft for the honor. I’m gonna do my best to continue contributing to the Data Platform community. And perhaps a few contributions to the Powershell community in the year to come.
PASS
The sad news about PASS taking its last breath on January 15th 2021 leave more questions than answers. Will anyone take over SQL Saturday? Will anyone take over PASS Summit, the largest Data Platform conference in the world? And do we need a global organisation for the Data Platform community? We will see. But I do know that PASS driven events took me to where I am today. My first Data conference was SQL Rally Nordic, in Denmark. That’s when I started thinking about public speaking. A PASS Usergroup was my first SQL related presentation. And PASS SQL Saturday was the first time I presented on a conference.
Thank you PASS for all these years. And thank you all amazing people within the Data Community. #SqlFamily will remain, we’re yet to see in which shapes.
Health
Despite all the professional development and all the community work I have done in 2020, the most important has been my personal health. After some stressful years of starting my company, commuting for hours every day and working a lot more than what’s healthy, I see the period of working from home as a real blessing. I mean, I don’t see covid-19 as a blessing, but the consequences has been that I’m home a lot more than before, I spend a lot more time with my family and I picked up running again.
Running. That used to be an important part of my life. But I haven’t prioritised it for years. I have eaten unhealthy food and I have gained weight. In just a few years, I put on 25kg. When I started working from home, I weighed more than 100kg, with a Body Mass Index of 32,5 (obesity). After working from home (or from my nearby office room), I have lost 14kg and my Body Mass Index is now at 28. It’s still considered Overweight, but it’s a lot better than 32,5. And I love running again. The last seven days of 2020, I have run every day. And I’m not finished. My goals for 2021, which I’m sure I will meet, is to loose another 10kg and to run a marathon before 2021 is over.
2021
I don’t know what 2021 will bring, other than what I said in the previous paragraph. I do know that there will be abother Data Weekender event. And that there will be SQL Friday events. I’m sure before 2021 is over, there will be in-person Data events to visit as well. I have already made a promise to be on the front row when Nikola Ilic makes his first in-person conference presentation, so I guess that’s one conference (wherever it may be) that I will visit.
But the biggest take-away from 2021 is to not plan too far ahead. Plans change. Some changes are minor, some or huge. And we will see change in 2021 as well.
I have worked quite a bit (too much?) with SQL Server replication. It has mostly been Transactional Replication and less Merge Replication.
A very common scenario I come across in both real life and in forum discussions is SQL Server Replication and Availability Groups.
This is the first in a short series of posts about replication and Availability Groups. As time permits, I will also finish posts on the Distributor and Subscriber roles in Availability Groups and finalize with a post on war stories from trying to move a distributor and subscribers from standalone instances to Availability Groups.
I’m not going to give very detailed instructions. That’s already well described in official documentation. Use this page as a starting point: https://docs.microsoft.com/en-us/sql/database-engine/availability-groups/windows/configure-replication-for-always-on-availability-groups-sql-server?view=sql-server-ver15
Instead I’m gonna try to summarize which scenarios are supported and which are not supported and a brief overview of the steps included. I will also share some of my experience too, gotchas and success factors.
Setup Publisher in Availability Group
A publisher can be part of an availability group. Both transactional replication and merge replication are supported scenarios.
Assuming you have already setup the distributor, these are the steps. Order does matter. I’m also assuming you have already setup the Availability Group before configuring replication publisher. If that’s not the case, aka you have already setup a publisher and then add them to availability group, this is also supported and you will just have to skip the steps that have to do with setting up the primary replica as publisher in this list.
Install replication features on all replicas.
Configure the primary replica and all secondary replicas as publishers in the distributor (with sp_adddistpublisher).
Configure the distributor at all replicas (with sp_adddistributor).
Enable the database(s) for replication (with sp_replicationdboption) in the primary replica.
(Documentation say linkedserver-connections are to be setup from publisher to push subscribers. I don’t do this, and more specifically, I don’t always know which subscribers I will have when I setup publications).
On distributor, redirect publisher to Availability Group Listener name (using sp_redirect_publisher)
Validate redirection works (with sp_validate_replica_hosts_as_publishers). This step will fail for secondary replicas not setup for read access.
It might come out as strange that the validation step fails. Usually you don’t want red errors in your result. But to get rid of red errors in the validation, you will need to pay additional enterprise licenses for the secondary replicas. If you won’t use the secondary replicas for read-only workloads, it’s not gonna be worth spending the extra money on additional enterprise licenses.
Test, test, test
I strongly encourage you to test this scenario and also test failing over to all secondary replica hosts.
On a busy system, you will have very, very, very nasty side effects when your publisher isn’t able to send stuff to the distributor. You will see transaction logs fill up and you will see replication as log_reuse_wait_desc in sys.databases. What that means is your transaction logs will grow, grow and then grow some more, until there’s no more disk to grow on and your databases will stop. If you miss this, and get a call in the middle of the night (these things always happen around 2AM) you’re gonna find yourself in a fun situation. A fast way to get rid of traces of replication is to set DB to single recovery mode and then run sp_removedbreplication. But it’s an Availability Group your dealing with here, and simple recovery mode doesn’t play well with Availability Groups. So your other option will be to reconfigure replication on the now primary replica, publish something and then remove replication. Either way, you’re into a mess you don’t want to deal with in production.
Script, script, script
As part of your setting up replication publishers on Availability Groups in your sandbox environment (that is where you should start, if you don’t have such environment, create one, it’s worth the effort and money), create scripts and make sure those scripts work.
Script to setup replication.
Script to add secondary replicas including setting up replication on them.
Script to fail back to your original primary replica (where you have a greater chance of logreader agents actually working and not filling up transaction logs).
Script to remove all traces of replication.
The script to remove all traces of replication is an important one. It might have to start with enabling replication, with the distribution database on the publisher and then removing it, as some commands to remove replication won’t work if you can’t reach the distributor.
It doesn’t matter if you create SQL-scripts, Powershell scripts or anything else. But please do what you can to automate creating and destruction of replication. Test these scripts. Not just the normal flow, but the odd quirky ones too. Test from the DR-site, to make sure you have firewalls open to everything you need. Test on all replicas. Test what happens when distributor is offline.
Monitor, monitor, monitor
There are a million ways to monitor your SQL Server environment. Choose your favourite flavour. But make sure to monitor your replication setup. Monitor transaction log usage on the publisher side. If your published databases’ transaction log usage remains high after transaction log backups, you want to set off alarms. You want to monitor messages from the Log Reader Agents. Your Log Reader Agents might seem to work just fine, in the way that they are in a running state. That doesn’t mean they are sending anything at all to the distributor. Try to monitor end-to-end. Does an inserted or changed row from a published table in the publisher end up in the distributor? If it doesn’t, you have a problem. And you want to solve that problem before your index maintenance jobs start filling up the transaction log the next night.
Do I hate replication?
Reading my warnings above, it might look like I hate SQL Server replication. That’s not the case. Transactional replication is a much cheaper solution than readonly AG secondaries for reporting scenarios. And you can choose to replicate only the stuff you need for reporting instead of the whole database. And you can add your reporting-specialised indexes on your reporting database. And, and, and…
But be careful. You don’t want to called in at 2AM because your production database died. Especially if the reason it failed is because you weren’t careful.
Data Community Weekender, Data Weekender or #DataWeekender. We did the first edition on May 2nd and we’re back October 17th with the second edition, the sequel or #TheSQL if you like. Register here: https://www.meetup.com/DataWeekender/events/272258429/
For those of you who didn’t attend Data Weekender in May, Data Weekender is a free, online conference all about Microsoft Data Platform.
On our first event, we had 42 sessions on six different tracks and over 600 attendees in total. We organised the event in more or less just four weeks, from announcing the Call for Speakers to selecting sessions and running the conference. It was a lot of work, not much sleep and tons of fun. We also received really good feedback, much thanks to our lovely volunteers that helped moderating sessions and various other tasks.
This time around, we thought we’d give ourselves a little more time, and therefore we announce it more than two months in advance. It’s still going to be tons of work and not much sleep. This time, like the first time, we run Data Weekender on a zero budget, meaning we don’t accept any sponsors. All the costs involved are covered by us on the organising team. Most of all that means we don’t have a marketing budget and therefore have to rely on ourselves to try to reach out on LinkedIn, Twitter and Facebook about it.
Changes
Although we think our first episode of Data Weekender was really successful (it really was, way, way better than we ourselves expected), we are making a few changes this time. I can’t reveal everything yet, mainly because not everything is settled, but some of the changes are:
We will push the schedule to a slightly later time, to allow for more speakers and attendees from North and South America. Not much though, we still want to make it possible for attendees and speakers from Australia, New Zealand, Asia, Africa and Europe to be able to attend.
We will arrange the tracks a little differently, more on that later.
The organising team will be put to the test, not only as organisers. You will be able to influence that. And I’m honestly a little scared about it.
Finally, it’s live. I hoped to announce the birth of SQL Friday on #tsql2sday but I simply didn’t have time for it. But now the site is live and speakers are queueing up for it.
What is SQL Friday?
SQL Friday is a weekly Friday lunch session, where a community speaker joins me in a Teams-meeting to present a Microsoft Data Platform or #SQLFamily related topic. The sessions are recorded and put on Youtube (and on the site).
The schedule is announced well ahead of time, but the full session details is announced and the registration opens up for next week’s SQL Friday just as this week’s SQL Friday finishes.
How do I attend SQL Friday?
You join the Meetup group created for SQL Friday, and register to attend to the session you’re interested in. https://meetup.com/Sql-Friday
This post is a contribution to this month’s T-SQL Tuesday (hashtag #tsql2sday on Twitter). Glenn Berry is this month’s host, and the topic is: “What you have been doing as a response to COVID-19”, as described in Glenn’s blog post T-SQL Tuesday #126 – Folding@Home.
I’m thinking of two contributions I’ve been working on for the community we know as SQL Family. One being planned, TGI SQL Friday, a friday lunch talk about Microsoft Data Platform, with one other member of the SQL Family as a guest. But this post is going to be about Data Community Weekender Europe, better known #DataWeekender.
I had been looking forward to 2020 as my most active year as a speaker. I have been in contact with local user groups in Europe, to whom I was going to pay a visit. I have submitted way more session abstracts to SQL Saturdays and other conferences than any previous year. Then came Covid-19. SQL Saturday Croatia was postponed. SQL Saturday Stockholm was cancelled. Trips to user groups were obviously cancelled. You get the pattern.
When looking at Twitter, I saw Kevin Chant (B | T) gathering interested parties to a virtual conference. Two tweets later, I was one of the six organisers of Data Community Weekender Europe, better known as #DataWeekender or Data Weekender. This was April 9th. The other organisers had already come up with the name of the conference and setup Call for Speakers in Sessionize. After that, it’s been hard work.
We had a number of challenges to overcome, many of them technical.
But before getting any of that up, we needed speakers. Without speakers, there wouldn’t be much of a conference. A discussion we had on an early stage was: “Should we as organisers submit sessions to the conference?” We decided we could, but wanted to wait to see how many abstracts were submitted before deciding. We had a record short Call for Speakers period, from April 8th to April 17th. That’s ten days. We felt it was a bit short, but to realistically have the conference on May 2nd, we couldn’t extend CfS-period further. Thus the decision we would all submit a session each if needed, to make it at least two tracks on the conference.
Wow. Were we wrong. There was absolutely no need to submit sessions ourselves. It turns out we had excellent channels to reach potential speakers, and our tweets and LinkedIn-posts about the conference reached out amazingly well (thank you everyone who tweeted and retweeted on an early stage!). By the end of CfS-period, we had almost 200 excellent sessions to choose from.
Next dilemma: With so many fantastic session abstracts submitted, from 76 speakers, how on earth were we to select sessions? We had discussed running two, maybe three tracks. We ended up with six parallel tracks, a total of 42 really good sessions, many of them from the most well-known speakers in the industry.
April 22nd, we made the schedule public. By then, we had roughly 150 registered attendees. We are all experienced community organisers and we know the no show-rate on any free event is 40-60%. That would leave is with roughly 75 attendees, for a six-track conference. Not impressive. The day we published the schedule, we got another 80 or so attendees registered. But we still had a long way to go and the days following April 22nd were pretty slow on registrations (50 or less per day).
Then something happened on April 27th, less than a week before the conference. We got 155 registrations on the same day. And an average of 100 registered attendees per day the following days.
This didn’t just happen. Between the six of us on the organising team, we probably tweeted 500 times with the hashtag #DataWeekender. We Posted around 100 LinkedIn-posts. We got in touch with all user groups we could find and told them about the event. We told people on the largest Facebook-groups about the event. Our Twitter account @DataWeekender started sending out tweets with dance-gifs every time we hit an even 50 or 100 registered attendees. And those tweets reached out.
I have to mention the help we got from volunteers as well. Both with promotion before the conference, but perhaps most importantly, all the help we received on the day of the event. If it’d just been the six of us, we would have been moderating one track each all day, without any way to answer support speakers during the day. We had setup WhatsApp-groups for the speakers of all the six tracks, to quickly reach speakers and give them a direct contact with one of the organisers. But without help with session moderation, it would have been useless, nobody can multitask that much in the middle of an ongoing session. So a yuuuuuuuuuuuuge Thank You to all the volunteers! ❤❤❤❤❤❤❤
Now the event day seems long gone, though it’s just ten days ago. We have been distributing speaker feedback to all the speakers and we evaluated the event feedback we got. And we are already talking about next iteration. Should we run it in another timezone? What else do we need to change (not much tbh, we feel really comfortable with the format). When will it happen? Does that make you curious? Sign up on the MeetUp-group Data Community Weekender and you’ll be the first to know!
Until next time: Thank You everyone who participated in any way to make the inaugural a complete success!
Organising team for Data Weekender:
Magnus Ahlkvist (B | T) Kevin Chant (B | T) Gethyn Ellis (B | T) Mark Hayes (B | T) Asgeir Gunnarsson (B | T) Damir Matesic (B | T)
The past ten days, I have spent quite some time promoting the virtual conference Data Community Weekender Europe, or #DataWeekender on May 2 2020. I’m one of six organizers, all people from the Microsoft Data community, better known as #sqlfamily. We saw conferences get cancelled or postponed and wanted to do something for the members of the community, speakers as well as conference attendees. So we came up with the idea to organize a virtual conference – #DataWeekender.
We are not alone, EightKB is another new Microsoft Data Platform conference, in June. And GroupBy is happening as usual in May. (I have submitted sessions to both, and for GroupBy, you are very welcome to vote for my session, as their sessions are picked by the community, not the organizers).
But #DataWeekender is probably the conference with the shortest time from idea to conference day. We opened up Call for Speakers April 8 and the conference is May 2. Given that short timeframe, I’m completely blown away by the number and quality of submissions. Doing session selections has been extremely difficult. If we created a new conference, with only the speakers and sessions we unfortunately had to reject, it would still be a very respectable conference schedule.
We still have a lot of work to do the coming less than two weeks leading up to the conference. And during the actual conference, the whole organising team will be busy moderating sessions. And until then, we need to test out conference technology, distribute and get confirmation on tons of information to speakers. And last but absolutely not least, we need to continue marketing the conference to attendees.
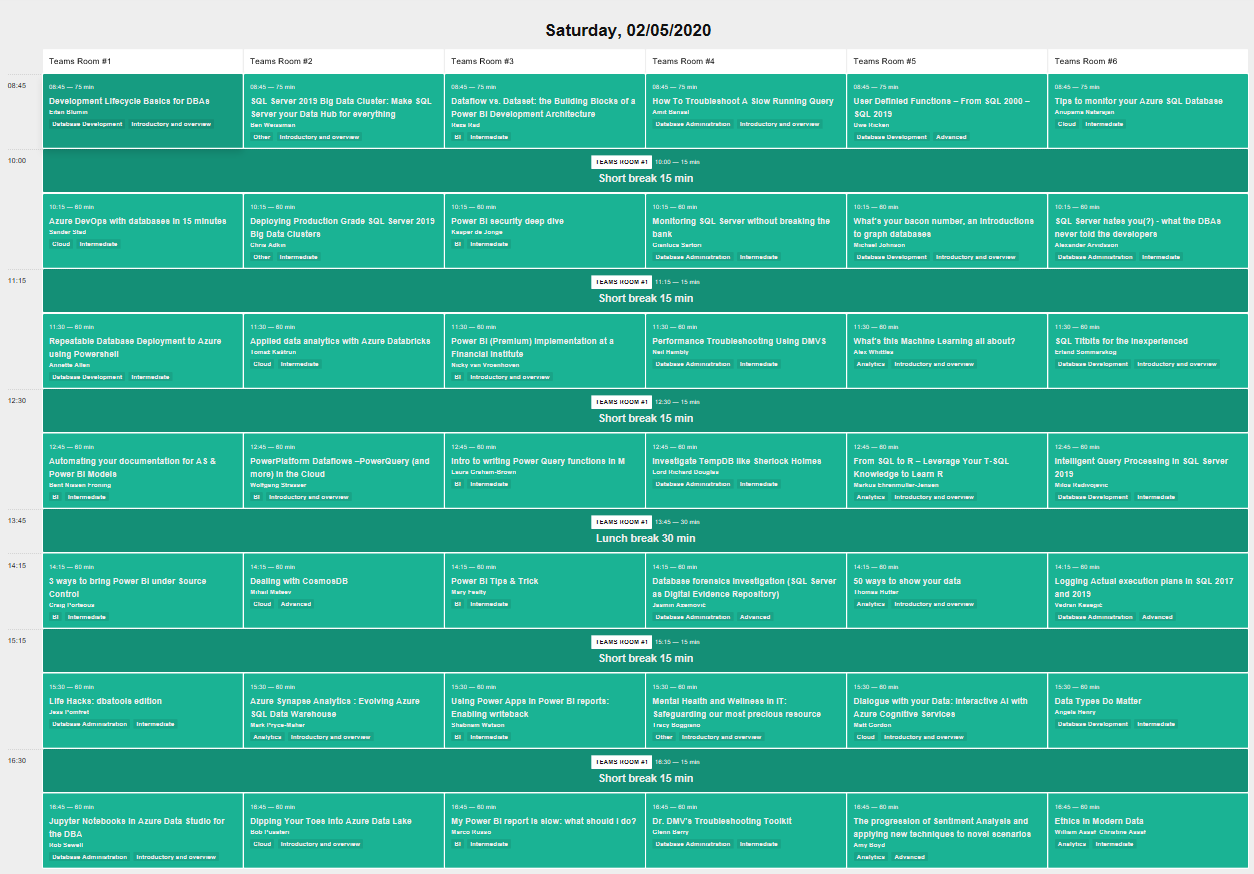
A very important milestone in the conference planning is now done. We have a schedule! Six tracks. 42 sessions. 43 speakers. Check it out on www.dataweekender.com/schedule ! Also checkout the speaker wall below, click on speaker name to see their bio and session.
#DataWeekender is running on a zero budget. We haven’t accepted any sponsors and we are not charging anyone to attend. Speakers get a Thank You, and bragging rights for getting selected. But nobody is paid anything. That makes marketing a little different than commercial conferences. We also do not have the Sql Saturday platform to channel information to the community. Instead, we are relying on our contacts with User Groups all over Europe and our social media channels.
Therefore, I ask from you to help promoting the conference. The schedule will be up on www.dataweekender.com late tomorrow. Whenever you see information about #DataWeekender in your social media feeds, please help us share the information. We would be very happy if you also make a post on your own about it. The speaker line-up is truly an impressive one, with MVPs, Certified Masters, Microsoft Employees and other amazing Data Platform presenters. Please help us get that known to the Data Platform community. I’m going to be more active than usual on the blog, sharing news not suited for the Twitter limited number of characters.